이번 글에서는 JAX에서 샤딩을 이용한 병렬화를 담당하는 시스템인 GSPMD에 대해서 알아봅시다.

NOTE
- 해당 글은 구글이 2021년 발표한 GSPMD 논문을 바탕으로 작성되었습니다. 해당 글과 함께 원 논문도 읽어보시길 추천드립니다.
- 이 시리즈에서는 다차원 배열 구조를 단순히 배열이라고 부르나, 이 글에서는 원 논문의 용어를 따라서 텐서tensor 라는 용어를 사용하겠습니다.
들어가기 전 - 실행 환경
이번 글의 모든 코드는 kaggle의 TPU v3-8 notebook 환경에서 실행되었습니다. Kaggle notebook 환경에서 이 글에 사용된 코드들을 직접 돌려보실 수 있습니다.
GSPMD란
GSPMD란 General and Scalable Parallelization for ML Computation Graph의 약자로, 계산 그래프를 몇 개의 텐서 어노테이션을 통해서 병렬화하는, 컴파일러 기반 자동 병렬화 시스템입니다. 생소한 용어들이 몇 가지 보이니 먼저 이들을 정의해 봅시다.
계산 그래프computation graph란 프로그램을 연산과 값들의 그래프로 표현한 것입니다. 예를 들어, 아래 코드의 퍼셉트론 함수는 그림 2와 같은 계산 그래프로 표현할 수 있습니다. (수행되는 연산을 정확히 밝히기 위해 브로드캐스팅broadcasting 을 명시적으로 수행해 주었습니다.)
import jax
import jax.numpy as jnp
import numpy as np
def perceptron(x, w, b):
# x의 차원: AB
# w의 차원: BC
# b의 차원: C
# out의 차원: AC
out = jnp.dot(x, w)
# b를 AC 로 브로드캐스트
# jax.lax.broadcast(array, dims)는 배열의 앞에 dims만큼의 차원을 추가함
# 예시: jax.lax.broadcast(np.ones((2, 4)), [8, 16])
# -> (8, 16, 2, 4) 형태로 브로드캐스트
b = jax.lax.broadcast(b, [x.shape[0]])
out += b
return out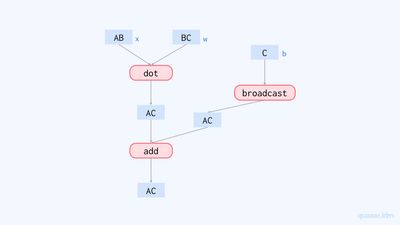
텐서 어노테이션tensor annotation은 계산 그래프 상 특정 텐서의 샤딩을 명시하는 것입니다. 컴파일러는 사용자가 준 텐서 어노테이션을 바탕으로 전체 그래프 상 텐서들의 샤딩을 자동으로 결정하고, 디바이스 별 프로그램을 생성하는 병렬화를 수행합니다. 이 과정에서 필요한 디바이스간 통신 연산 삽입 및 최적화는 컴파일러가 자동으로 수행해줍니다.
GSPMD의 이점
GSPMD의 이점은 병렬 코드를 직관적이고 효율적으로 작성할 수 있다는 것입니다. 복잡한 병렬화 과정을 컴파일러가 담당하기 때문에 사용자는 싱글 디바이스 프로그램을 작성하는 것처럼 멀티 디바이스 프로그램을 작성할 수 있습니다. 또한, 필요할 시 사용자는 텐서 어노테이션을 통해서 병렬화 과정에 개입할 수 있으며, 이를 통해 batch parallelism, pipeline parallelism 등 다양한 병렬화 패턴들을 손쉽게 표현할 수 있습니다. 효율성의 측면에서 살펴보자면, GSPMD를 트랜스포머 모델에 적용할 시 모델 크기 및 배치 크기에 따른 메모리 사용량이 선형적으로 증가합니다. (그림 3) 이러한 장점 덕분에, GSPMD를 활용하면 거대한 언어 모델을 직관적이고 효율적으로 훈련시키는 것이 가능합니다.

JAX와 GSPMD
GSPMD는 JAX에서 바로 사용할 수 있습니다. JAX의 기반이 되는 XLA 컴파일러가 GSPMD의 구현을 포함하며, 지난 글에서 살펴보았던 연산의 자동 병렬화 기능도 XLA 컴파일러의 GSPMD 시스템으로 구현되는 기능입니다. 아래 예시 코드를 봅시다.
from jax.sharding import Mesh, NamedSharding, PartitionSpec
mesh = Mesh(np.array(jax.devices()).reshape(2, 4), ("x", "y"))
x = np.ones((48, 24))
w = np.ones((24, 48))
b = np.ones((48,))
y = jax.jit(
perceptron,
in_shardings=(
NamedSharding(mesh, PartitionSpec("x", None)),
NamedSharding(mesh, PartitionSpec(None, "y")),
NamedSharding(mesh, PartitionSpec())
),
out_shardings=NamedSharding(mesh, PartitionSpec())
)(x, w, b)
위 코드에서 JIT된 함수를 호출 시 XLA 컴파일러는 함수 perceptron을 컴파일합니다. 이때 샤딩이 명시되었으므로 컴파일러는 GSPMD 시스템을 통해서 해당 함수를 병렬화합니다. 즉, jax.jit()과 샤딩을 통해서 손쉽게 GSPMD를 사용할 수 있는 것입니다.
GSPMD의 작동 방식
JIT의 4가지 과정
GSPMD에 대해 본격적으로 알아보기에 앞서, JIT된 함수를 호출할 시 무슨 일이 일어나는지 알아봅시다.
JAX는 jax.jit()으로 감싸진 함수를 호출 시 다음과 같은 과정을 수행합니다.
- Stage out - 파이썬 함수를 JAX 내부 표현으로 변환 (이 과정을 트레이싱tracing 이라 합니다.)
- Lower - 트레이싱된 함수를 XLA 컴파일러가 이해하는 입력 언어인 StableHLO로 변환
- Compile - XLA 컴파일러가 실행 파일을 생성
- Execute - 컴파일된 실행 파일을 디바이스상에서 실행
1번과 2번 과정을 거치면서 파이썬 함수는 배열과 기초적인 선형대수 연산들로만 이루어진 함수 표현으로 변환됩니다. 즉 함수의 계산 그래프를 생성하는 것입니다.
앞서 정의한 perceptron 함수를 직접 stage out 및 lower 시켜봅시다.
lowered = jax.jit(
perceptron,
in_shardings=(
NamedSharding(mesh, PartitionSpec("x", None)),
NamedSharding(mesh, PartitionSpec(None, "y")),
NamedSharding(mesh, PartitionSpec())
),
out_shardings=NamedSharding(mesh, PartitionSpec())
).lower(x, w, b)
print(lowered.as_text("stablehlo"))module @jit_perceptron attributes {mhlo.num_partitions = 8 : i32, mhlo.num_replicas = 1 : i32} {
func.func public @main(%arg0: tensor<48x24xf32> {mhlo.sharding = "{devices=[2,1,4]<=[8] last_tile_dim_replicate}"}, %arg1: tensor<24x48xf32> {mhlo.sharding = "{devices=[1,4,2]<=[2,4]T(1,0) last_tile_dim_replicate}"}, %arg2: tensor<48xf32> {mhlo.sharding = "{replicated}"}) -> (tensor<48x48xf32> {jax.result_info = "", mhlo.sharding = "{replicated}"}) {
%0 = stablehlo.dot_general %arg0, %arg1, contracting_dims = [1] x [0], precision = [DEFAULT, DEFAULT] : (tensor<48x24xf32>, tensor<24x48xf32>) -> tensor<48x48xf32>
%1 = stablehlo.broadcast_in_dim %arg2, dims = [1] : (tensor<48xf32>) -> tensor<48x48xf32>
%2 = stablehlo.add %0, %1 : tensor<48x48xf32>
return %2 : tensor<48x48xf32>
}
}
jax.jit()으로 감싸진 함수는 lower() 메소드를 가집니다. 이 메소드를 함수의 입력값들과 함께 호출하면 stage out 및 lower된 함수를 나타내는 객체인 Lowered 객체를 얻을 수 있으며, 해당 객체의 as_text() 메소드를 이용해 텍스트 형식의 표현을 얻었습니다. (as_text()의 인자는 출력 형식을 의미합니다.)
출력된 문자열은 Stage out 후 Lower된 함수의 StableHLO 표현입니다. 이 함수 표현을 간단히 살펴봅시다. 1번째 줄은 @jit_perceptron이란 모듈을, 2번째 줄은 @main 함수를 선언합니다. 함수는 48x24 크기의 인수 %arg0, 24x48 크기의 인수 %arg1, 48 크기의 인수 %arg2를 받습니다. 이는 각각 변수 x, w, b을 나타내는 것으로, 크기가 일치하는 것을 확인할 수 있습니다. 또한 출력값은 48x48의 크기를 가집니다.
이어서 3번째 줄 부터는 인수들에 대한 연산이 수행됩니다. 먼저 3번째 줄에서는 dot_general 연산을 %arg0, %arg1에 대해서 수행하며, 4번째 줄에선 편향 %arg2를 broadcast_in_dim 연산으로 브로드캐스팅합니다. 그리고 5번째 줄에선 내적의 결괏값과 브로드캐스팅된 편향을 add 연산으로 더해줍니다. 이 결과값이 마지막 6번째 줄에서 반환되고 함수는 종료됩니다.
앞서 말했듯이, 이 함수 표현은 계산 그래프라고도 볼 수도 있습니다. 위의 함수 표현을 바탕으로 계산 그래프를 그려보면 다음과 같습니다.
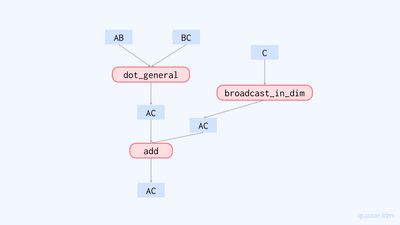
이렇게 얻은 계산 그래프는 XLA 컴파일러에 의해 컴파일된 후 실행됩니다. Lowered 객체의 compile() 함수를 호출해 명시적으로 함수를 컴파일할 수 있습니다.
compiled = lowered.compile()
compiled.as_text()HloModule jit_perceptron, is_scheduled=true, entry_computation_layout={(f32[24,24]{1,0:T(8,128)}, f32[24,12]{0,1:T(8,128)}, f32[48]{0:T(256)})->f32[48,48]{1,0:T(8,128)}}
(생략)
ENTRY %main.9_spmd (param: f32[24,24], param.1: f32[24,12], param.2: f32[48]) -> f32[48,48] {
%param.2 = f32[48]{0:T(256)} parameter(2), sharding={replicated}
%param.1 = f32[24,12]{0,1:T(8,128)} parameter(1), sharding={devices=[1,4,2]<=[2,4]T(1,0) last_tile_dim_replicate}
%param = f32[24,24]{1,0:T(8,128)} parameter(0), sharding={devices=[2,1,4]<=[8] last_tile_dim_replicate}
%fusion.2 = f32[1,24,12]{1,2,0:T(8,128)} fusion(f32[24,24]{1,0:T(8,128)} %param, f32[24,12]{0,1:T(8,128)} %param.1), kind=kOutput, calls=%fused_computation.2, metadata={op_name="jit(perceptron)/jit(main)/dot_general[dimension_numbers=(((1,), (0,)), ((), ())) precision=None preferred_element_type=float32]" source_file="/tmp/ipykernel_13/1107513741.py" source_line=11}, backend_config={"flag_configs":[],"window_config":{"kernel_window_bounds":["2","1"],"output_window_bounds":["2","1"],"input_window_bounds":["3","1"],"estimated_cycles":"1003","iteration_bounds":["1","1","1"]},"scoped_memory_configs":[]}
%all-gather.2 = f32[8,24,12]{1,2,0:T(8,128)} all-gather(f32[1,24,12]{1,2,0:T(8,128)} %fusion.2), channel_id=2, replica_groups={{0,1,2,3,4,5,6,7}}, dimensions={0}, use_global_device_ids=true, metadata={op_name="jit(perceptron)/jit(main)/add" source_file="/tmp/ipykernel_13/1107513741.py" source_line=19}, backend_config={"flag_configs":[],"barrier_config":{"barrier_type":"CUSTOM","id":"0"},"scoped_memory_configs":[],"collective_algorithm_config":{"emitter":"1DAllGatherOnMajorDim","debug":"\ngroup_size = 8\nper_stride_size = 8192 bytes\nshard_size = 8192 bytes"}}
(생략)
이전과 마찬자기로, compile() 메소드는 Compiled 객체를 반환하며 이 객체의 as_text() 메소드를 호출해 컴파일된 프로그램의 HLO 표현을 얻을 수 있습니다. 컴파일된 프로그램의 표현은 굉장히 복잡하므로 이를 모두 해석하는 대신 특징적인 부분 몇 가지만을 살펴보도록 합시다. 먼저 ENTRY로 표시된 진입점 함수의 인자를 살펴보면, 첫 번째 인자의 크기가 48x24가 아니라 24x24인 것을 볼 수 있습니다. 이는 배열 x가 2x4 메쉬의 첫 번째 차원에 대해 샤딩되었기 때문으로 (샤드의 크기가 24x24), 이는 위 프로그램은 샤딩된 배열이 아니라 샤드 각각을 인자로 받는다는 것을 의미합니다. 즉 위 코드는 하나의 디바이스 위에서 샤딩된 텐서의 샤드에 대해서 연산을 수행하는 디바이스별 프로그램이란 것입니다. 이어서 맨 마지막에서 두 번째 줄을 보면 all-gather 연산이 사용된 것을 볼 수 있습니다. 이로부터 컴파일러가 연산에 필요한 디바이스별 통신 명령을 추가하다는 것도 알 수 있습니다.
컴파일된 프로그램을 보며 알 수 있는 것들을 정리하자면 병렬화는 컴파일 과정에서 일어나며, 컴파일러는 하나의 계산 그래프를 입력으로 받아 각 디바이스별 계산 그래프를 생성한다는 것입니다. 그리고 컴파일러에서 병렬화를 담당하는 핵심 시스템이 바로 GSPMD입니다. 즉, GSPMD의 입출력은 다음과 같습니다.
- 입력: 하나의 계산 그래프
- 출력: 각 디바이스별 계산 그래프
이제 GSPMD 시스템의 입출력을 정의했으니, 병렬화가 어떻게 수행되는지 알아봅시다. 이는 크게 두 과정을 통해 이루어집니다.
- 샤딩 완성
- 파티셔닝
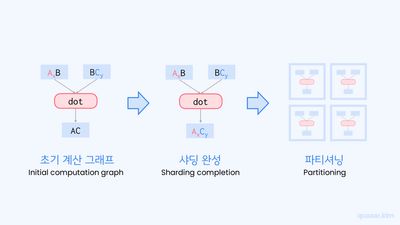
먼저 샤딩 완성 과정부터 알아봅시다.
샤딩 완성
샤딩 완성sharding completion 과정에서는 사용자가 명시한 텐서 어노테이션을 이용해 계산 그래프 상 모든 텐서의 샤딩을 결정합니다.
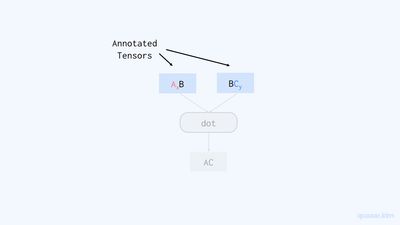
앞서 말했듯이, 텐서 어노테이션을 통해 사용자는 계산 그래프 상 특정 텐서들의 샤딩을 정할 수 있습니다. GSPMD 시스템은 텐서 어노테이션으로 명시된 샤딩을 순전파forward propagation 및 역전파backward propagation 시키길 반복하며 그래프 위의 모든 텐서들의 샤딩을 결정합니다. 이때 연산의 입력 텐서가 서로 다른 샤딩을 가질 때에는 (가능한 경우) 이들을 병합하고, 이를 출력 텐서의 샤딩으로 삼습니다.
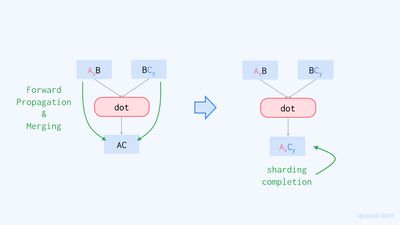
샤딩의 전파 순서는 연산별 중요도에 따라서 결정됩니다. 이는 효율적인 계산을 위해 디바이스간 통신을 최대한 줄이기 위해서입니다. 분량 관계상 이 글에서는 해당 내용을 다루지 않으니, 더 알고 싶으시다면 원 논문의 섹션 3.5를 참조하시길 바랍니다.
코드 예시
실제로 JAX에서는 어떻게 샤딩이 완성되는지 코드를 돌려보며 알아봅시다. JIT된 함수 내부에 jax.debug.inspect_array_sharding() 함수 호출을 삽입하면 프로그램이 실행될 때 배열이 어떻게 샤딩되어 있는지 확인해 볼 수 있습니다.
from functools import partial
def perceptron_with_sharding_inspection(x, w, b):
jax.debug.inspect_array_sharding(x, callback=partial(print, "input x sharding:"))
jax.debug.inspect_array_sharding(w, callback=partial(print, "input w sharding:"))
jax.debug.inspect_array_sharding(b, callback=partial(print, "input b sharding:"))
out = jnp.dot(x, w)
jax.debug.inspect_array_sharding(out, callback=partial(print, "output of dot sharding:"))
b = jax.lax.broadcast(b, [x.shape[0]])
jax.debug.inspect_array_sharding(b, callback=partial(print, "broadcasted b sharding:"))
out += b
jax.debug.inspect_array_sharding(out, callback=partial(print, "output sharding:"))
return out
jax.jit(
perceptron_with_sharding_inspection,
in_shardings=(
NamedSharding(mesh, PartitionSpec("x", None)),
NamedSharding(mesh, PartitionSpec(None, "y")),
NamedSharding(mesh, PartitionSpec())
),
out_shardings=NamedSharding(mesh, PartitionSpec())
)(x, w, b);input x sharding: GSPMDSharding({devices=[2,1,4]<=[8] last_tile_dim_replicate}, memory_kind=tpu_hbm)
input w sharding: GSPMDSharding({devices=[1,4,2]<=[2,4]T(1,0) last_tile_dim_replicate}, memory_kind=tpu_hbm)
input b sharding: GSPMDSharding({replicated}, memory_kind=tpu_hbm)
output of dot sharding: GSPMDSharding({devices=[2,4]0,1,2,3,4,5,6,7}, memory_kind=tpu_hbm)
broadcasted b sharding: GSPMDSharding({replicated}, memory_kind=tpu_hbm)
output sharding: GSPMDSharding({replicated}, memory_kind=tpu_hbm)
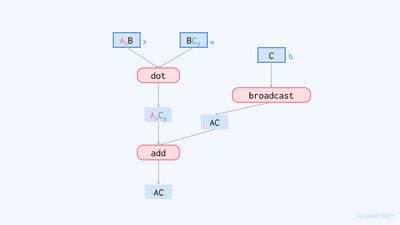
프로그램 중간에 샤딩을 출력할 경우 NamedSharding 대신 GSPMDSharding이 출력됩니다. GSPMDSharding은 이름에서 알 수 있듯이 GSPMD이 인식하는 배열의 샤딩을 표현하는 샤딩 클래스입니다. 먼저 입력값 x의 샤딩의 devices 필드를 살펴보면 [2,1,4]<=[8]으로 출력되는데, 이는 0부터 8개의 숫자들로 이루어진 배열을 만들고, 이를 2x1x4의 크기로 변경하라는 의미입니다. (numpy로 표현하면 np.arange(8).reshape(2, 1, 4)와 동일합니다.) 이 필드는 샤딩이 이루어지는 메쉬를 의미하며, 각 숫자는 디바이스의 인덱스를 의미합니다. 즉 이 샤딩은 2x1x4 메쉬에 대한 샤딩이라는 의미입니다. 또한, last_tile_dim_replicate라는 속성이 붙어 있는데, 이는 디바이스 배열의 마지막 차원에 대해서 복제가 이루어진다는 의미입니다. 결국 이 샤딩은 in_shardings에 명시해준 첫 번째 인자의 샤딩 (NamedSharding(mesh, PartitionSpec("x", None)))과 동일한 샤딩입니다.
출력된 입력값 w의 샤딩도 in_shardings의 두 번째 인자의 샤딩과 동일합니다. [1,4,2]<=[2,4]T(1,0)은 2x4 메쉬를 전치시킨 4x2 메쉬를 1x4x2 크기로 변경한다는 의미입니다. 입력값 b의 샤딩 또한 in_shardings에 명시해 준 샤딩과 동일한 샤딩을 가지는 것을 확인할 수 있습니다.
주목해야 할 부분은 내적의 결과와 브로드캐스된 편향의 샤딩입니다. 내적의 결과의 샤딩의 devices 필드 [2, 4]0,1,2,3,4,5,6,7은 0~7의 숫자를 2x4로 재배열한 메쉬를 의미하며, last_tile_dim_replicate 속성이 없으므로 이 샤딩은 배열을 2x4 메쉬에 대해 완전히 샤딩시킵니다. 이를 파티션 스펙으로 표현하면 PartitionSpec("x", "y")에 해당합니다. 그리고 브로드캐스트된 편향은 샤딩되지 않았습니다. 이 결과를 계산 그래프로 나타내면 다음과 같습니다.
이번에는 샤딩 어노테이션을 사용해 보겠습니다. jax.lax.with_sharding_constraint() 함수를 JIT된 함수 내부에 사용해 함수 중간에 샤딩 어노테이션을 사용할 수 있습니다. 한편, jax.jit() 함수 호출의 in_shardings 및 out_shardings 인자 또한 샤딩 어노테이션에 해당합니다.
def perceptron_with_sharding_inspection(x, w, b):
jax.debug.inspect_array_sharding(x, callback=partial(print, "input x sharding:"))
jax.debug.inspect_array_sharding(w, callback=partial(print, "input w sharding:"))
jax.debug.inspect_array_sharding(b, callback=partial(print, "input b sharding:"))
out = jnp.dot(x, w)
+ out = jax.lax.with_sharding_constraint(out, NamedSharding(mesh, PartitionSpec("x", None)))
jax.debug.inspect_array_sharding(out, callback=partial(print, "output of dot sharding:"))
b = jax.lax.broadcast(b, [x.shape[0]])
jax.debug.inspect_array_sharding(b, callback=partial(print, "broadcasted b sharding:"))
out += b
jax.debug.inspect_array_sharding(out, callback=partial(print, "output sharding:"))
return out
jax.jit(
perceptron_with_sharding_inspection,
in_shardings=(
NamedSharding(mesh, PartitionSpec("x", None)),
NamedSharding(mesh, PartitionSpec(None, "y")),
NamedSharding(mesh, PartitionSpec())
),
out_shardings=NamedSharding(mesh, PartitionSpec())
)(x, w, b);input x sharding: GSPMDSharding({devices=[2,1,4]<=[8] last_tile_dim_replicate}, memory_kind=tpu_hbm)
input w sharding: GSPMDSharding({devices=[1,4,2]<=[2,4]T(1,0) last_tile_dim_replicate}, memory_kind=tpu_hbm)
input b sharding: GSPMDSharding({replicated}, memory_kind=tpu_hbm)
output of dot sharding: GSPMDSharding({devices=[2,1,4]<=[8] last_tile_dim_replicate}, memory_kind=tpu_hbm)
broadcasted b sharding: GSPMDSharding({replicated}, memory_kind=tpu_hbm)
output sharding: GSPMDSharding({replicated}, memory_kind=tpu_hbm)
위 코드는 내적의 결과가 PartitionSpec("x", None)에 해당하는 샤딩을 가지도록 강제합니다.
이번 글에서는 GSPMD가 무엇인지, 그리고 샤딩 완성 과정에 대해서 알아보았습니다. 다음 글에서는 GSPMD의 파티셔닝 과정을 알아보고, GSPMD를 이용해서 자연어 처리 분야에 흔히 사용되는 트랜스포머 모델을 병렬화하는 방법에 대해 다루겠습니다.
읽어주셔서 감사합니다.