JAX는 병렬 연산을 위해 두 가지의 서로 다른 스타일의 API를 제공합니다.
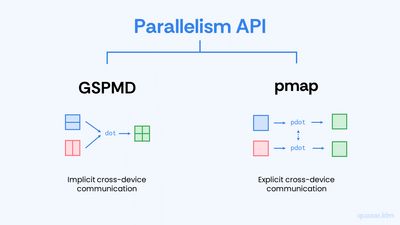
GSPMD API는 배열을 여러 디바이스에 걸쳐 나누는 기능 (이를 샤딩sharding 이라 합니다)을 제공합니다. 그리고 이렇게 샤딩된 배열들에 대한 연산을 어떻게 수행할지는 XLA 컴파일러가 결정하게 합니다. 즉 코드가 all-gather, all-reduce 등의 디바이스 간 통신cross-device communication 을 직접 호출하지 않으며, 대신 컴파일러가 프로그램을 컴파일하는 과정에서 통신 코드를 알아서 넣어줍니다.
pmap API를 사용할 때에는 디바이스 간 통신을 명시적으로 호출해 줘야 합니다. 해당 API에서는 하나의 디바이스에 작동하는 함수를 작성하고 이를 jax.pmap() 변환을 통해 모든 디바이스에서 작동하는 프로그램으로 변환시키는 방식으로 병렬화를 지원합니다. 이때 함수는 명시적으로 디바이스 간 통신 코드를 호출해야 합니다.
GSPMD vs. pmap
두 병렬 연산 API는 서로 다른 관점에서 설계되었습니다.

pmap API를 사용할 때에는 각 디바이스별 코드를 작성합니다. 그렇기 때문에 디바이스간 통신 코드 또한 직접 작성해 줘야 하는 것이죠. 이러한 관점은 상당히 직관적이며 (PyTorch의 병렬화 API와 비슷합니다), 직접 디바이스 간 통신 코드를 작성하는 만큼 성능상 이점이 있을 수 있습니다. 하지만 복잡한 병렬화 패턴을 구현할 때에는 이 부분이 상당히 번거로울 수 있습니다.

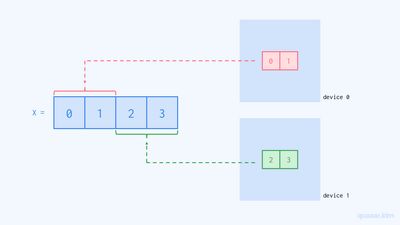
GSPMD API에서는 각 디바이스별 코드를 작성하지 않습니다. 해당 API에서는 배열을 샤딩시킴으로써 하나의 배열이 여러 디바이스에 걸쳐 존재할 수 있도록 할 수 있습니다. 예를 들어, 만약 x = [0 1 2 3]이라는 배열이 있다면 해당 배열의 앞 부분([0 1])은 0번 디바이스에, 뒷 부분([2 3])은 1번 디바이스에 존재하도록 할 수 있으며, 이러한 실제 데이터의 위치와 무관하게 이 배열은 여전히 하나의 배열 객체로 표현됩니다. (그림 4)
즉 GSPMD API에서는 디바이스들을 하나의 거대한 디바이스라는 관점으로 바라보며, 이 디바이스 하나에서 작동하는 코드를 작성합니다. 그렇기 때문에 디바이스 간 통신 코드 또한 직접 작성할 필요가 없습니다. 애초에 모든게 하나의 디바이스에 있는 셈이나 마찬가지이기 때문이죠. 이러한 관점은 처음에는 굉장히 낯설게 느껴질 수 있으며, 디바이스 간 통신 코드가 컴파일러에 의해 자동으로 삽입되는 만큼 비효율적일 수 있습니다. 하지만 이 API의 진가는 복잡한 병렬화 패턴을 구현할 때 드러납니다. Data Parallel, Pipeline Parallel 등 다양한 병렬화 패턴들을 유연하게 표현 가능하며, 여러 대의 컴퓨터를 사용해 연산을 수행해야 하는 멀티-호스트multi-host 환경에서도 마치 싱글 호스트 환경처럼 코딩할 수 있습니다.
코드 예시
실제 병렬 연산을 수행하는 코드를 각각의 방법으로 구현해 보며 두 API를 비교해 보도록 하겠습니다. 간단하게 2x2 행렬을 만들고, 각 원소의 제곱을 두 개의 디바이스에서 나눠서 계산해 봅시다.
먼저 2x2 행렬을 만들어줍니다.
import numpy as np
import jax
print("devices:", jax.devices())
x = np.arange(4).reshape(2, 2)
print("x:", x)devices: [cuda(id=0), cuda(id=1)]
x: [[0 1]
[2 3]]pmap
def f(arr):
return arr**2
jax.pmap(f)(x)Array([[0, 1],
[4, 9]], dtype=int32)
pmap API에서는 디바이스별 코드를 작성합니다. 위 코드에서 함수 f()는 배열을 받아 각 원소를 제곱한 결과를 반환하는 간단한 함수입니다. 이는 jax.pmap() 변환을 통해 모든 디바이스에서 병렬적으로 실행되도록 변환된 후 `x`에 대해서 호출되어 결과적으로 x의 제곱을 병렬적으로 계산합니다.
여기서 눈여겨보아야 할 것은 디바이스 별 코드를 작성했다는 것입니다. 함수 f()가 디바이스별 코드에 해당합니다.
GSPMD
from jax.sharding import Mesh, NamedSharding, PartitionSpec
devices = np.array(jax.devices())
mesh = Mesh(devices, ("x",))
y = jax.device_put(x, NamedSharding(mesh, PartitionSpec("x", None)))
z = y ** 2
zArray([[0, 1],
[4, 9]], dtype=int32)
GSPMD API에서는 디바이스별 코드를 작성하지 않습니다. 대신 배열을 여러 디바이스에 걸쳐 나누고, 나누어진 배열을 일반적인 배열처럼 다룹니다.
위 코드에서는 먼저 디바이스들의 매쉬mesh 를 만들었습니다. 라인 3에서는 디바이스 객체들로 이루어진 배열을 만들었고, 라인 4에서는 이를 이용해 Mesh 객체를 만들었습니다. 앞으로 이 매쉬 객체는 하나의 거대한 디바이스처럼 취급할 수 있습니다.
이어서 라인 6에서는 배열 x를 디바이스 매쉬에 대해서 샤딩해 주었습니다. jax.device_put()은 첫 번째 인자로 배열을 받고, 두 번째 인자로 이 배열을 어떻게 나눌 것인지를 명시하는 Sharding 객체를 받습니다. 이 객체에 대해서는 다음 글에서 다루고자 하므로 여기서는 자세히 설명하지 않겠지만, 대략적인 뜻은 배열 x를 첫 번째 디바이스가 [0 1]을, 두 번째 디바이스가 [2 3]을 가지도록 나누라는 의미입니다.
라인 7에서는 샤딩된 배열 y에 대해서 바로 제곱 연산을 사용해 주었습니다. 해당 연산은 컴파일 과정에서 자동으로 병렬화되어 실행됩니다. 최종 결과인 z를 확인해 보면 위의 pmap API 사용시와 동일한 결과를 얻은 것을 볼 수 있습니다.
내 생각
저는 LLM 구현을 위해 앞으로 GSPMD API를 사용할 예정입니다. 앞서 언급했듯이 해당 API는 복잡한 병렬화 패턴을 굉장히 간단히 구현할 수 있도록 해주는데, LLM에 흔히 사용되는 트랜스포머Transformer 아키텍쳐를 효율적으로 병렬화하기 위해서는 해당 API를 사용하는 것이 pmap보다 훨씬 간단하고 직관적입니다.
다음 글에서는 배열을 여러 디바이스에 대해서 나누는 방법을 제공하는 jax.sharding API에 대해서 다루도록 하겠습니다.
읽어주셔서 감사합니다.
해당 글에 사용된 코드는 kaggle notebook 환경에서 돌려보실 수 있습니다.
참고문헌
JEP 14273: shard_map for simple per-device code - GSPMD API와 pmap API의 중간 성격을 가진shmap이라는 API를 소개하는 제안안입니다. 사실 JAX 공식 문서에는 서로 다른 스타일의 병렬화 API들이 있다는 것을 제대로 알려주지 않습니다. 대신 해당 제안안의 도입 부분에서 해당 부분에 대해 자세히 다루니 읽어보시는 것을 추천합니다.