이번 글에서는 JAX 배열을 여러 디바이스에 걸쳐 나누고, 계산하는 방법을 알아봅시다.
들어가기 전 - 실행 환경
이번 글의 모든 코드는 kaggle의 TPU v3-8 notebook 환경에서 실행되었습니다. Kaggle notebook환경에서 이 글에 사용된 코드들을 직접 돌려보실 수 있습니다.
import jax
jax.devices()[TpuDevice(id=0, process_index=0, coords=(0,0,0), core_on_chip=0),
TpuDevice(id=1, process_index=0, coords=(0,0,0), core_on_chip=1),
TpuDevice(id=2, process_index=0, coords=(1,0,0), core_on_chip=0),
TpuDevice(id=3, process_index=0, coords=(1,0,0), core_on_chip=1),
TpuDevice(id=4, process_index=0, coords=(0,1,0), core_on_chip=0),
TpuDevice(id=5, process_index=0, coords=(0,1,0), core_on_chip=1),
TpuDevice(id=6, process_index=0, coords=(1,1,0), core_on_chip=0),
TpuDevice(id=7, process_index=0, coords=(1,1,0), core_on_chip=1)]샤딩 이해하기
jax.sharding API
이전 글에서 소개했듯이, GSPMD API는 배열을 여러 디바이스에 걸쳐 자르는 (샤딩하는) 기능을 제공합니다. 이러한 기능은 jax.sharding 패키지를 통해 사용할 수 있습니다.
먼저 4x4 크기의 배열을 만들어줍시다.
import numpy as np
x = np.ones((4, 4))이 배열을 샤딩하기 위해서는 다음 질문들에 대해 답해야 합니다.
- 배열을 어떤 디바이스들에 대해서 나눌 것인가?
- 각 디바이스가 무슨 데이터를 가지게 할 것인가?
JAX에선 이러한 정보를 Sharding이라는 객체로 표현합니다. 배열을 어떤 디바이스들에 대해서 나눌 것인지를 나타내는 메쉬를 만들고, 이를 다른 정보들과 합쳐 배열을 샤딩하는 방법을 나타내는 샤딩 객체를 만들 수 있습니다.
먼저 메쉬를 만들어 봅시다.
from jax.sharding import Mesh
devices = np.array(jax.devices()).reshape(2, 4)
mesh = Mesh(devices, ("x", "y"))
가장 먼저 디바이스 객체들로 이루어진 2x4 크기의 배열을 생성합니다. 그리고 이 배열을 이용해 Mesh 객체를 만듭니다. Mesh 객체는 디바이스들의 배열과 배열의 각 차원의 이름을 저장하는 단순한 객체로, 생성 시 두번째 인자로 각 차원에 이름을 붙여줄 수 있습니다. 여기서는 첫번째 차원에 "x", 두번째 차원에 "y"라는 이름을 붙여주었습니다.
NOTE
JAX에서는 디바이스 객체들로 이루어진 배열을 디바이스 메쉬device mesh, Mesh 객체를 논리 메쉬logical mesh라 부릅니다. 따라서 해당 시리즈에서도 이제부터 이 둘을 이와 같이 구분하려 합니다. 또한, 그냥 메쉬라고 할 경우에는 논리 메쉬를 뜻하는 것입니다.
그 다음으론 메쉬를 이용해 Sharding 객체를 만들어 줍시다.
from jax.sharding import NamedSharding, PartitionSpec
sharding = NamedSharding(mesh, PartitionSpec("x", "y"))
위 코드에선 샤딩의 일종인 NamedSharding을 만들어 주었습니다. 이 샤딩은 첫번째 인자로 메쉬를 받고, 두번째 인자로 메쉬와 배열을 어떻게 연관시킬지를 설명하는 PartitionSpec이라는 객체를 받습니다. (이에 대해선 조금 있다 자세히 알아보도록 합시다.)
샤딩 객체를 만들었으니 이제 배열을 샤딩할 수 있습니다.
y = jax.device_put(x, sharding)
y.devices(){TpuDevice(id=0, process_index=0, coords=(0,0,0), core_on_chip=0),
TpuDevice(id=1, process_index=0, coords=(0,0,0), core_on_chip=1),
TpuDevice(id=2, process_index=0, coords=(1,0,0), core_on_chip=0),
TpuDevice(id=3, process_index=0, coords=(1,0,0), core_on_chip=1),
TpuDevice(id=4, process_index=0, coords=(0,1,0), core_on_chip=0),
TpuDevice(id=5, process_index=0, coords=(0,1,0), core_on_chip=1),
TpuDevice(id=6, process_index=0, coords=(1,1,0), core_on_chip=0),
TpuDevice(id=7, process_index=0, coords=(1,1,0), core_on_chip=1)}
jax.device_put() 함수의 두 번째 인자로 샤딩 객체를 넣어 주면 이에 따라 샤딩된 배열이 반환됩니다. 샤딩된 배열 y의 devices() 메소드를 호출해 배열이 올라가 있는 디바이스들을 확인해 보면 8개의 디바이스들이 반환되는걸 확인할 수 있습니다.
NamedSharding의 이해
NamedSharding은 논리 메쉬를 이용해서 배열을 나누는 샤딩입니다.
그리고 논리 메쉬에 대해 배열을 어떻게 나눌 것인지를 결정하는 것이 PartitionSpec 객체입니다. PartitionSpec은 배열의 각 차원이 메쉬의 어떤 차원에 대해 나뉘어지는지를 정의하는 튜플입니다. 앞서 보았던 PartitionSpec("x", "y")는 배열의 0번째 차원을 메쉬의 차원 "x"에 대해서, 배열의 1번째 차원을 메쉬의 차원 "y"에 대해서 나눈다는 의미입니다.

배열의 0번째 차원을 메쉬의 차원 "x"에 대해 나눈다는 것은 0번째 차원을 나타내는 모든 1차원 배열들을 메쉬의 "x" 차원의 크기만큼의 조각으로 나눈다는 의미입니다. 앞서 보았던 4x4 배열을 2x4 메쉬에 대해 PartitionSpec("x", "y")으로 샤딩하는 상황을 생각해봅시다. 먼저 0번째 차원을 나타내는 1차원 배열을 메쉬의 "x" 차원의 크기인 2개의 조각으로 나눕니다. (그림 2 왼쪽), 그 다음으론 1번째 차원을 나타내는 1차원 배열들 4개를 모두 메쉬의 "y" 차원의 크기인 4개의 조각으로 나누어 줍니다. (그림 2 오른쪽)
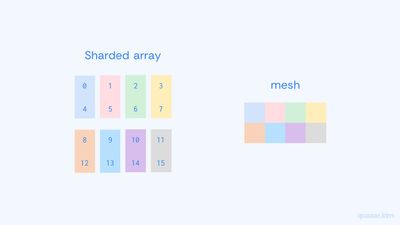
샤딩된 배열의 조각들은 그림 3과 같이 메쉬와 동일한 모양을 가지게 됩니다. 여기서 각 조각을 샤드shard라고 하며, 각 샤드는 메쉬의 디바이스로 배치됩니다.
다양한 샤딩 패턴들
NamedSharding은 파티션 스펙에 따라 다양한 샤딩 패턴을 표현할 수 있습니다. 몇 가지 샤딩 패턴들을 알아봅시다.
PartitionSpec("x", None)

파티션 스펙에는 메쉬 차원의 이름 외에도 None이 들어갈 수 있습니다. 이는 해당 차원은 어떤 메쉬 차원에 대해서도 샤딩하지 않겠다는 의미로, 해당 차원은 나눠지는 대신 남은 메쉬 차원 "y"에 대해 복제됩니다.
PartitionSpec()
이 파티션 스펙은 배열을 어느 차원에 대해서도 나누지 않습니다. 따라서 배열은 메쉬의 모든 디바이스에 대해서 복제됩니다.
PartitionSpec("y", "x")
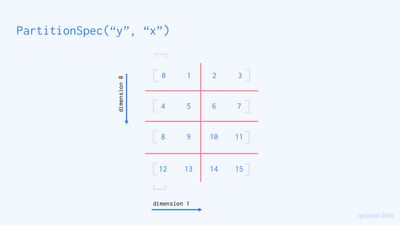
앞서 본 PartitionSpec("x", "y")에서 메쉬의 차원 순서를 꼬아주었습니다. 이와 같이 메쉬의 차원의 순서는 얼마든지 바뀔 수 있습니다. (단 중복은 불가능합니다.)
이상으로 다양한 샤딩 패턴들을 알아보았습니다. 여기서 소개한 샤딩 패턴들 외에도 다양한 샤딩 패턴들이 존재합니다. 다음 코드 셀에 다루지 못한 파티셔닝 스펙 몇 가지를 제시해 두었으니 이것들이 배열을 어떻게 나눌 것인지 한번 생각해보시길 바랍니다. (힌트를 드리자면, 다음 파티셔닝 스펙 중 하나는 유효하지 않습니다.)
PartitionSpec("y", None)
PartitionSpec(None, "x")
PartitionSpec(None, "y")
PartitionSpec("x", "x")연산의 자동 병렬화
샤딩된 배열이라 해서 일반적인 배열과 다르게 다룰 필요는 없습니다. 샤딩된 배열도 JAX 연산에 바로 사용 가능합니다.
x = np.ones((48, 24))
x = jax.device_put(x, NamedSharding(mesh, PartitionSpec("x", None)))
y = np.ones((24, 48))
y = jax.device_put(y, NamedSharding(mesh, PartitionSpec(None, "y")))
z = x @ y
print("shape:", z.shape)
print("sharding:", z.sharding)shape: (48, 48)
sharding: NamedSharding(mesh=Mesh('x': 2, 'y': 4), spec=PartitionSpec('x', 'y'), memory_kind=tpu_hbm)
위 코드에선 ("x", None)으로 샤딩된 배열 x와 (None, "y")으로 샤딩된 배열 y를 만들고, 둘의 행렬곱 z를 계산했습니다. 여기서 눈여겨보아야 할 점은 두가지입니다. 먼저 샤딩된 배열들을 일반적인 배열과 같이 바로 계산에 사용했습니다. 이러한 상황에선 XLA 컴파일러가 자동으로 연산을 병렬화하고, 디바이스간 통신을 수행하는 코드를 생성합니다.
두번째 중요한 점은 배열 x와 y가 다른 파티션 스펙을 가지고 있다는 것입니다. 이러한 상황에서 XLA 컴파일러는 중간값과 결과값들의 샤딩을 정해진 규칙들에 의해 자동으로 선택합니다. 이러한 규칙을 "연산이 데이터를 따른다"(computation follows data)고 합니다. 위 코드에선 행렬곱 결과 x의 1번째 차원, y의 0번째 차원이 없어진다는 것을 고려해 z의 샤딩으로 파티션 스펙 ("x", "y")를 가지는 NamedSharding이 자동으로 결정되었습니다.
jax.jit으로 함수 병렬화하기
jax.jit()으로 컴파일된 함수도 샤딩된 배열과 함께 사용할 수 있습니다.
import jax.numpy as jnp
def f(x, w, b):
return (x @ w) + b
x = np.ones((48, 24))
x = jax.device_put(x, NamedSharding(mesh, PartitionSpec("x", None)))
w = np.ones((24, 48))
w = jax.device_put(y, NamedSharding(mesh, PartitionSpec(None, "y")))
b = np.ones((48,))
b = jax.device_put(b, NamedSharding(mesh, PartitionSpec()))
y = jax.jit(f)(x, y, b)
print("shape:", y.shape)
print("sharding:", y.sharding)shape: (48, 48)
sharding: NamedSharding(mesh=Mesh('x': 2, 'y': 4), spec=PartitionSpec('x', 'y'), memory_kind=tpu_hbm)이와 같이, 샤딩된 배열을 컴파일된 함수의 인자로 넘겨주면 앞서 보았던것과 마찬가지로 자동으로 병렬화 및 디바이스간 통신 수행이 이루어집니다.
함수의 입력 샤딩 및 출력 샤딩을 컴파일 시 명시하는것도 가능합니다.
def f(x, w, b):
return (x @ w) + b
x = np.ones((48, 24))
w = np.ones((24, 48))
b = np.ones((48,))
y = jax.jit(
f,
in_shardings=(
NamedSharding(mesh, PartitionSpec("x", None)),
NamedSharding(mesh, PartitionSpec(None, "y")),
NamedSharding(mesh, PartitionSpec())
),
out_shardings=NamedSharding(mesh, PartitionSpec())
)(x, w, b)
print("shape:", y.shape)
print("sharding:", y.sharding)shape: (48, 48)
sharding: NamedSharding(mesh=Mesh('x': 2, 'y': 4), spec=PartitionSpec(), memory_kind=tpu_hbm)
jax.jit() 함수의 in_shardings 및 out_shardings 함수를 통해 입력 및 출력 샤딩을 정의할 수 있습니다. 그리고 입력값으로 numpy 배열들을 넘겨주면 이들은 자동으로 샤딩됩니다.
예시: 거대 퍼셉트론
실제 예시를 통해서 배열 샤딩이 어떻게 활동될 수 있는지 알아봅시다. 우리의 목표는 다음의 거대한 배열 x에 대해서 연산을 수행하는 퍼셉트론perceptron 함수를 만드는 것입니다. 이 퍼셉트론은 가중치 w와 b를 가진다고 합시다. 먼저 샤딩을 사용하지 않고 코드를 짜 봅시다.
def perceptron(params, x):
return jnp.dot(x, params["w"]) + params["b"]
params = {
"w": np.ones((65536, 32768), dtype=np.float32),
"b": np.ones((32768,), dtype=np.float32)
}
x = np.ones((65536, 65536), dtype=np.float32)
print("x:", x.nbytes / (1024**3), "GB")
print("w:", params["w"].nbytes / (1024**3), "GB")
print("b:", params["b"].nbytes / (1024**3), "GB")x: 16.0 GB
w: 8.0 GB
b: 0.0001220703125 GB
배열 x와 가중치 w의 크기가 터무니 없이 큽니다. 각각 16GB, 8GB의 메모리 공간을 차지합니다. 따라서 모든 배열을 하나의 디바이스에 올리기 위해선 디바이스의 메모리가 적어도 24GB 이상이여야 합니다. 하지만 제가 코드를 실행시키고 있는 TPU v3-8 환경의 각 TPU 코어들은 16GB 만큼의 메모리를 가지기 때문에 이 코드를 실행할 수 없습니다.
jax.jit(perceptron)(params, x)---------------------------------------------------------------------------
XlaRuntimeError Traceback (most recent call last)
Cell In[10], line 1
----> 1 jax.jit(perceptron)(params, x)
[... skipping hidden 14 frame]
File /usr/local/lib/python3.10/site-packages/jax/_src/compiler.py:256, in backend_compile(backend, module, options, host_callbacks)
251 return backend.compile(built_c, compile_options=options,
252 host_callbacks=host_callbacks)
253 # Some backends don't have `host_callbacks` option yet
254 # TODO(sharadmv): remove this fallback when all backends allow `compile`
255 # to take in `host_callbacks`
--> 256 return backend.compile(built_c, compile_options=options)
XlaRuntimeError: RESOURCE_EXHAUSTED: XLA:TPU compile permanent error. Ran out of memory in memory space hbm. Used 24.00G of 15.48G hbm. Exceeded hbm capacity by 8.52G.
...
실행 시 RESOURCE_EXHAUSTED 오류가 발생하는 것을 볼 수 있습니다.
이 코드가 성공적으로 실행되도록 배열과 가중치를 샤딩시켜 봅시다.
x = jax.device_put(x, NamedSharding(mesh, PartitionSpec("x", "y")))
params["w"] = jax.device_put(params["w"], NamedSharding(mesh, PartitionSpec("y", "x")))
params["b"] = jax.device_put(params["b"], NamedSharding(mesh, PartitionSpec()))
jax.jit(perceptron)(params, x)Array([[65537., 65537., 65537., ..., 65537., 65537., 65537.],
[65537., 65537., 65537., ..., 65537., 65537., 65537.],
[65537., 65537., 65537., ..., 65537., 65537., 65537.],
...,
[65537., 65537., 65537., ..., 65537., 65537., 65537.],
[65537., 65537., 65537., ..., 65537., 65537., 65537.],
[65537., 65537., 65537., ..., 65537., 65537., 65537.]], dtype=float32)코드가 메모리 부족 오류 없이 성공적으로 실행되었습니다. TPU v3-8은 각 디바이스 당 16GB, 총 128GB의 메모리를 가지고 있기 때문에 샤딩을 적절히 사용해준다면 메모리 문제 없이 계산을 수행할 수 있습니다.
이번 글에서는 배열을 샤딩하고, 계산을 수행하는 방법을 알아보았습니다. 다음 글에서는 JAX GSPMD API가 설계된 바탕인 GSPMD에 대해서 다루도록 하겠습니다.
읽어주셔서 감사합니다.
참고문헌
- Distributed arrays and automatic parallelization - 배열 샤딩에 대한 JAX 공식 튜토리얼입니다.